
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 스프링 부트3
- 프로그래머스
- oracle
- db
- 스프링 부트
- URI 원칙
- 차원증가
- Python
- 컬렉션 인터페이스
- 컬렉션 프레임웍
- 머신러닝
- conda remove
- 파이썬
- 알고리즘
- Java
- 오라클
- 자바 로그 레벨
- WinError5
- h2 데이타베이스
- 자바 열거형
- REST API
- 셀레니움
- openai
- 완주하지못한선수
- Selenium
- streamlit
- 쓰레드 풀
- GIT
- 사이킷런 회귀
- 사이킷런
- Today
- Total
노트 :
[Kaggle] Bike Sharing Demand 데이터 분석 시각화 본문
plt.subplots(figsize=(16,8))
sns.heatmap(bike_corr, annot=True, fmt='.2f', vmax=1, square=True)캐글은 전세계 데이터 사이언티스들을 위한 경진 사이트이다.
여러 기업이나 단체들이 과제를 등록하면, 누구나 사이트에서 참여가 가능하며, 우승자에게는 상금이 주어진다.
데이터 사이언티스들을 위한 사이트이므로, 분석을 위한 데이터가 풍부하며, 교육용 자료도 많다.
데이터 분석을 원한다면 캐글을 이용해보자.
오늘은 캐글 사이트의 자전거 대여 수요 파일을 분석해보고자 한다.
https://www.kaggle.com/competitions/bike-sharing-demand
사이트에서 train.csv를 다운로드 받으면 된다.
test.csv는 알고리즘 검증용, sampleSubmission.csv는 사이트에 본인이 분석한 내용을 제출하여 채첨받기 위한 파일이다.
우리는 train.csv 데이터만 사용하여 학습하고자 한다.
먼저, 판다스의 read_csv 함수를 사용하여 데이터를 로드한다.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline # 주피터 노트북에서 출력결과를 바로 보기 위해 사용
bike_train = pd.read_csv('./bike_train.csv')다음으로, 데이터의 전체적인 형태를 알아본다.
bike_train.shape
____________________
# (10886, 12)shape를 사용하자. 해당 데이터는 12칼럼, 10886행으로 구성되어 있다.
bike_train.info()
________________________________________________
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10886 entries, 0 to 10885
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 10886 non-null object # 대여시간
1 season 10886 non-null int64 # 계절 (1:봄, 2:여름, 3:가을, 4:겨울)
2 holiday 10886 non-null int64 # 휴일 (0:휴일아님, 1:휴일)
3 workingday 10886 non-null int64 # 월~금 (0:휴일, 1:휴일아님)
4 weather 10886 non-null int64 # 계절
5 temp 10886 non-null float64 # 기온
6 atemp 10886 non-null float64 # 체감기온
7 humidity 10886 non-null int64 # 습도
8 windspeed 10886 non-null float64 # 풍속
9 casual 10886 non-null int64 # 등록되지 않은 사용자가 대여한 수
10 registered 10886 non-null int64 # 등록한 사용자가 대여한 수
11 count 10886 non-null int64 # 자전거 대여수
dtypes: float64(3), int64(8), object(1)
memory usage: 1020.7+ KB
'''info함수를 사용하면, 칼럼의 내용 및 결측치와 자료형을 알 수 있다.
object는 문자형이며, 하나의 칼럼만 존재한다는 것을 알 수 있다.
결측치는 없어보이지만, isnull 함수를 사용하여 정확하게 알아보자.
bike_train.isnull().sum()
_________________________
'''
datetime 0
season 0
holiday 0
workingday 0
weather 0
temp 0
atemp 0
humidity 0
windspeed 0
casual 0
registered 0
count 0
dtype: int64
'''
결측치가 없는 깨끗한 데이터이다.
만약 결측치가 있다면, 해당 결측치를 해당 자료의 평균이나 0으로 대체한다.
결측치가 너무 많은 칼럼이라면, 해당 칼럼을 삭제하는 것이 나을 때도 있다.
bike_train.describe()실행하면, 아래와 같은 데이터 프레임이 뜰 것이다.
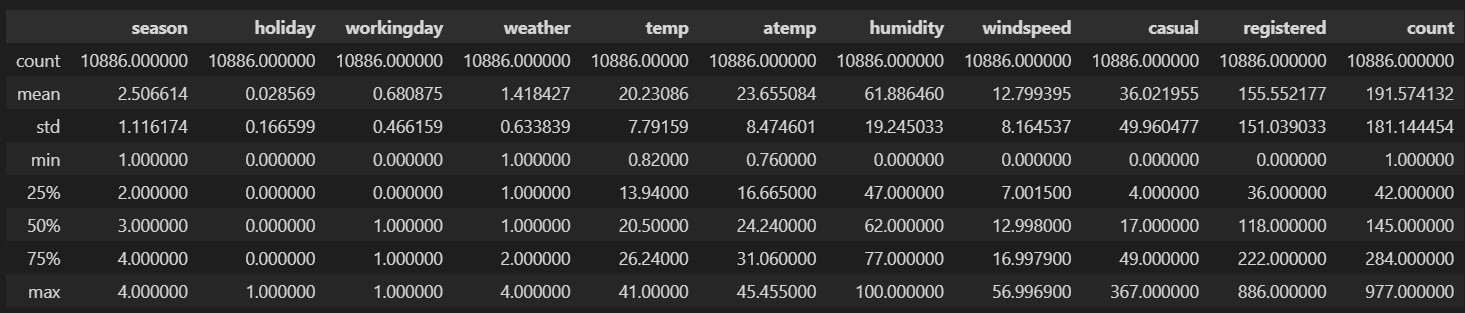
문자형인 datetime을 제외한 나머지 칼럼의 mean, std, min 등 통계를 알수 있다.
이제 head함수를 이용하여, 데이터를 살짝 엿보자. 인자를 지정하지 않으면, 맨 위 5개를 보여준다.
여기서는 10개를 보도록 하자.
bike_train.head(10)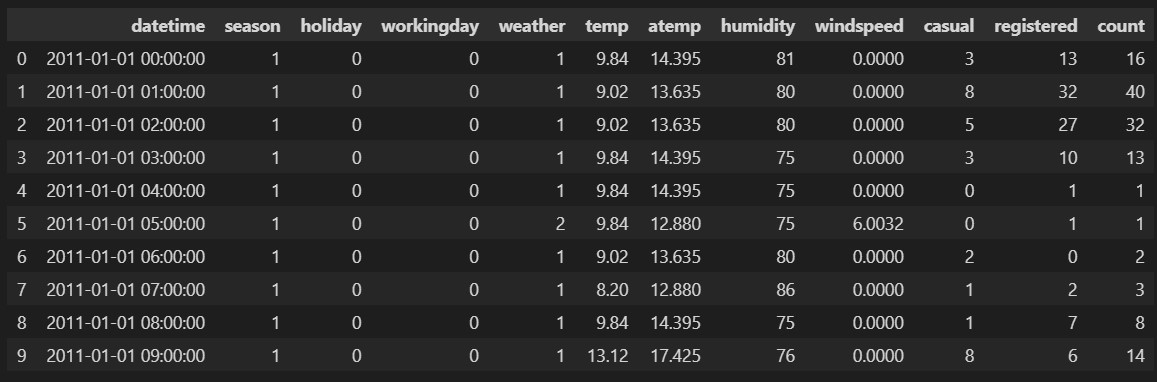
이제, 데이터 처리를 위해 datetime의 자료형을 datetime형으로 변환한 후, 연·월·일·시간으로 칼럼을 분할할 것이다.
bike_train['datetime'] = pd.to_datetime(bike_train['datetime'])
bike_train['year'] = bike_train['datetime'].dt.year
bike_train['month'] = bike_train['datetime'].dt.month
bike_train['day'] = bike_train['datetime'].dt.day
bike_train['hour'] = bike_train['datetime'].dt.hour
bike_train.head()다음으로, 필요없는 칼럼을 삭제하자.
datetime은 자료를 분리해서 연·월·일·시간으로 새로 만들었기 때문에 필요없다.
casual과 registered도 제거하자.
casual은 등록되지 않은 사용자가 대여한 수이며, registered는 등록되지 않은 사용자가 대여한 수이므로 두 수를 더하면 총 대여수량인 count와 같다. 데이터 시각화에서는 물론, 머신러닝/딥러닝을 적용하여 분석할 때는 분석치에 영향을 줄 수 있으므로 빼야한다.
bike_train = bike_train.drop(['datetime', 'casual', 'registered'], axis=1, inplace=False)
이제 bike_train을 출력해보면, year·month·day·time이 테이블의 맨 앞이 아니라 뒤에 가서 붙은 것을 알 수있다.
칼럼의 순서를 조정해보자.
bike_train = bike_train[['year', 'month', 'day', 'time', 'season', 'holiday', 'workingday', 'weather', 'temp', 'atemp', 'humidity', 'windspeed', 'count']]
bike_train이제 bike_train을 출력하면 아래와 같이 나올 것이다.
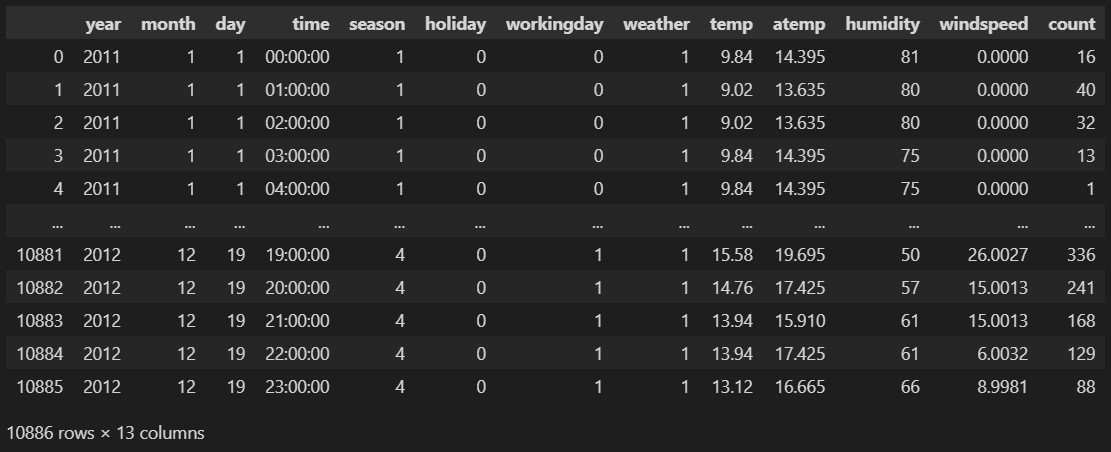
이제, 시각화를 할 준비가 다 되었다. 시각화를 해 보자.
fig, ((ax1, ax2, ax3), (ax4, ax5, ax6), (ax7, ax8, ax9)) = plt.subplots(figsize=(18, 12), nrows=3, ncols=3)
sns.barplot(data=bike_train, x='year', y='count', ax=ax1)
sns.barplot(data=bike_train, x='month', y='count', ax=ax2)
sns.barplot(data=bike_train, x='day', y='count', ax=ax3)
sns.barplot(data=bike_train, x='time', y='count', ax=ax4)
sns.barplot(data=bike_train, x='workingday', y='count', ax=ax5)
sns.barplot(data=bike_train, x='weather', y='count', ax=ax6)
sns.barplot(data=bike_train, x='temp', y='count', ax=ax7)
sns.barplot(data=bike_train, x='humidity', y='count', ax=ax8)
sns.barplot(data=bike_train, x='windspeed', y='count', ax=ax9)실행하면, 아래와 같이 예쁜 그래프가 나올 것이다.
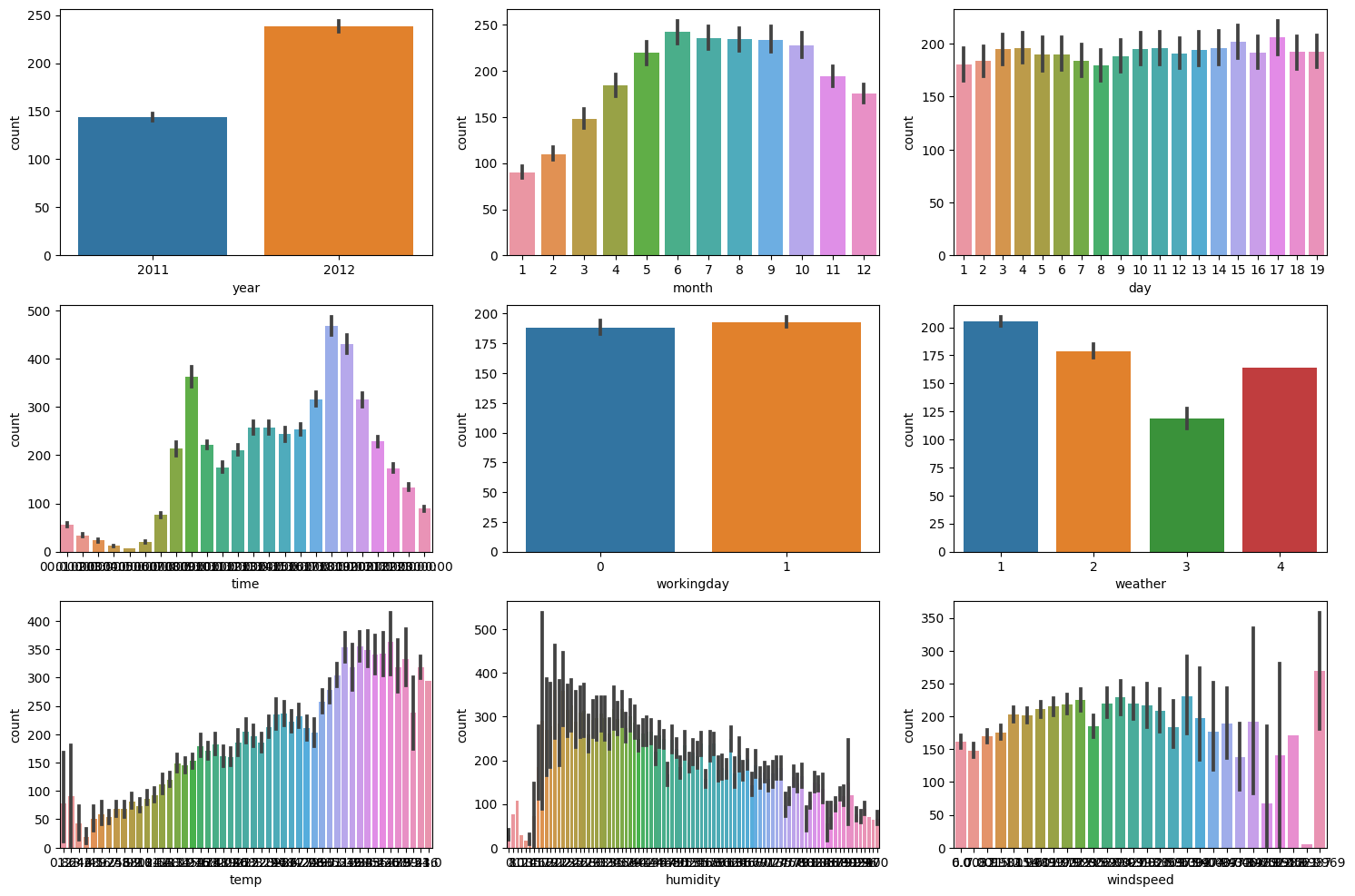
그래프를 보면, 해당 피처와 자전거 대여수의 관계를 직관적으로 알 수 있다.
month와 time, temp, humidity가 자전거 대여수와 관계가 있는 것처럼 보인다.
이제 히트맵으로 더욱 자세한 관계를 살펴보자.
그 전에 피처간의 상관관계에 대해 corr함수를 사용해서 알아볼 것이다.
bike_corr = bike_train.corr()
bike_corr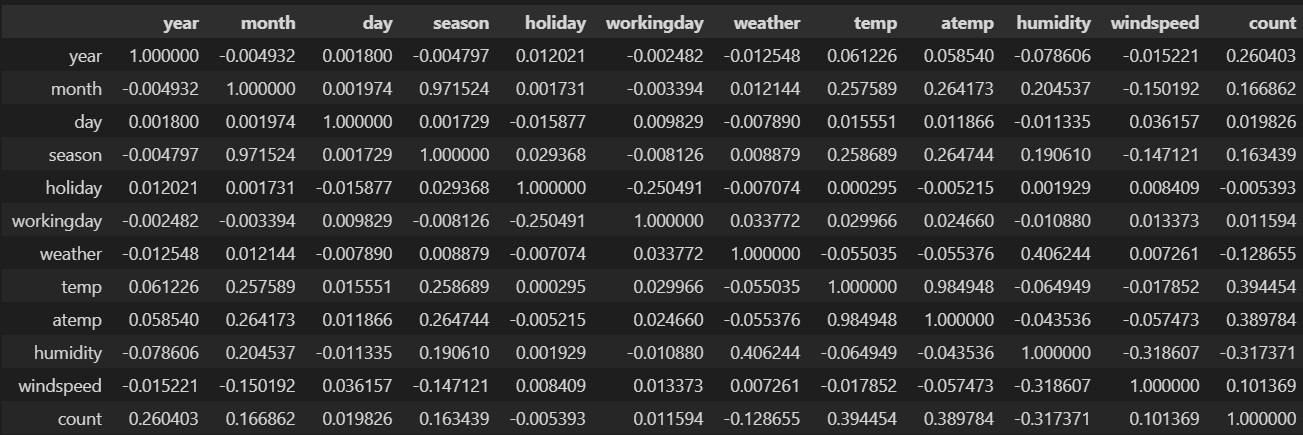
칼럼과 행이 겹치는 부분은 자기 자신이므로, 상관관계가 1인 것을 알 수 있다.
여기서 중요한 부분은 count와 다른 피처 간의 관계이므로 count 칼럼을 주의깊게 본다.
temp, atemp이 약 0.39의 양의 상관관계, humitidy가 -0.32로 음의 상관관계로, 나머지 피처들보다 높은 상관관계가 있다.
그러나, 0.5 이상의 높은 상관관계를 보이는 피처는 없다.
이제 히트맵으로 시각적으로 상관관계를 알아보자.
plt.subplots(figsize=(16,8))
sns.heatmap(bike_corr, annot=True, fmt='.2f', vmax=1, square=True)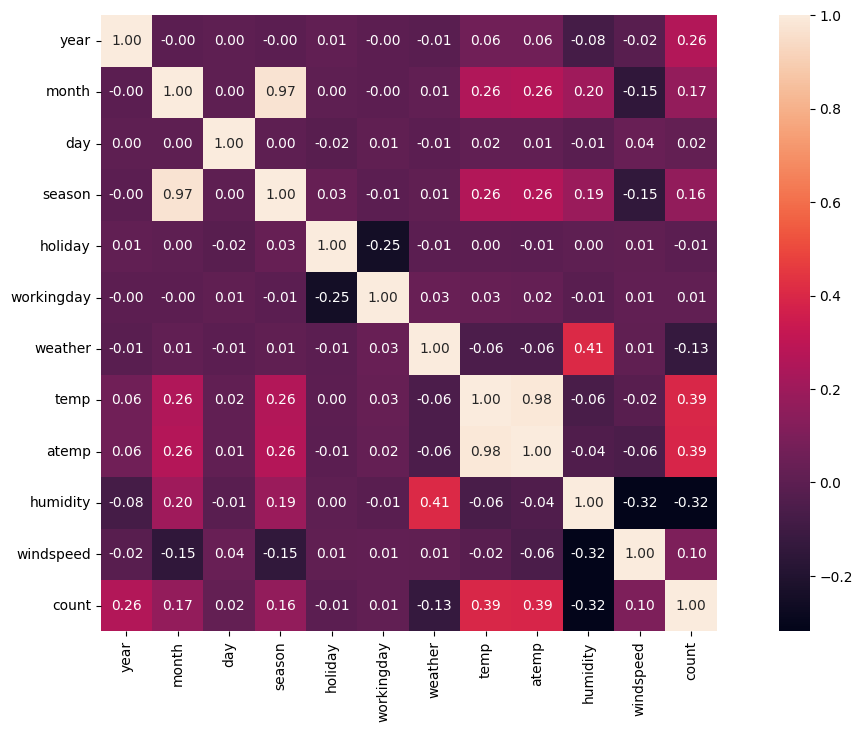
방금 본 상관관계를 그림으로 나타내니 훨씬 더 보기 쉽다.
개인적으로, 그래프보다 히트맵이 데이터 간의 관계를 알아보기 쉽다고 생각한다.
'ML' 카테고리의 다른 글
| 반응형 머신러닝 앱을 만드는 가장 빠른 방법 - gradio (0) | 2023.03.04 |
|---|---|
| DALL-E 2 (0) | 2023.03.03 |
| ChatGPT (0) | 2023.01.29 |
| ML - 사이킷런 (0) | 2022.11.27 |
| Google - Teachable Machine (0) | 2022.11.26 |



