
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 완주하지못한선수
- conda remove
- Java
- 프로그래머스
- 알고리즘
- db
- GIT
- h2 데이타베이스
- 셀레니움
- 오라클
- Selenium
- URI 원칙
- WinError5
- 컬렉션 프레임웍
- 파이썬
- 머신러닝
- streamlit
- 자바 로그 레벨
- 스프링 부트3
- REST API
- Python
- 자바 열거형
- openai
- oracle
- 사이킷런 회귀
- 쓰레드 풀
- 스프링 부트
- 차원증가
- 컬렉션 인터페이스
- 사이킷런
- Today
- Total
노트 :
Scikit-learn - 데이터 인코딩 본문
머신러닝을 위한 대표적인 인코딩 방식에는 2가지가 있다.
① 레이블 인코딩(Label Encoding)
: 카테고리 피처를 숫자 값으로 변환
② 원-핫 인코딩(One Hot Encoding)
: 피처의 개수만큼 칼럼을 만들어 고유값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시
1. 레이블 인코딩
(1) 방식

카테고리 피처인 제품분류를 0~5에 이르는 숫자 값으로 변환한다.
(2) 코드

사이킷런의 LabelEncoder 클래스를 임포트한 후, LabelEncoder 객체를 생성한다.
이후 fit()과 transform()의 인자에 리스트로 된 피처를 넣어서 변환한다.
결과값인 label을 출력해보면 ndarray인 [1, 3, 5, 4, 2, 0, 1, 5]가 출력된다.
해당 피처가 어떤 숫자 값을 가지는 지 알고 싶다면, classes_속성을 사용하면 된다.
위에서는 순서대로 갤럭시탭이 1, 노트북이 3, 스마트폰이 5...의 값을 가지게 된다.
2. 원-핫 인코딩
(1) 방식
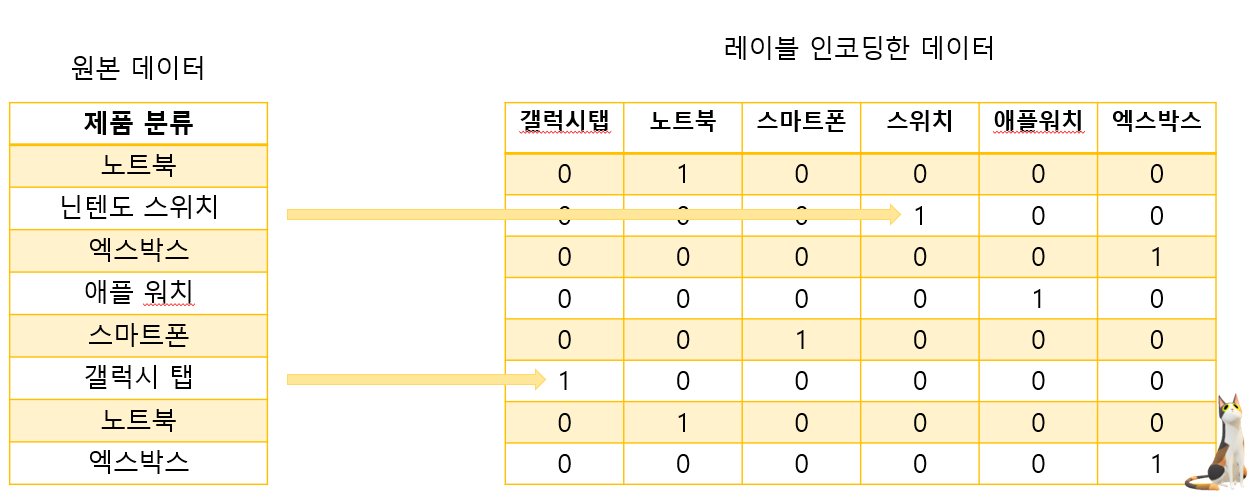
피처의 개수만큼 칼럼을 만들어 고유값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시한다.
(2) 코드

피처인 items는 레이블 인코딩 때와 같다.

원-핫 인코딩은 레이블 인코딩에 비해서 조금 복잡한데, 인자로 리스트가 아닌 2차원 ndarray로 넘겨줘야 한다.
또한, fit()과 transform()을 적용한 값이 원하는 결과가 아니기 때문에 해당 결과에 toarray()메서드를 한번 더 적용해줘야 한다.
이는 transform()한 결과가 희소행렬(Sparse Matrix)이기 때문에 toarray()메서드를 이용해 원하는 밀집행렬(Dense Matrix)로 변환해주기 위함이다.
위의 코드에서 보면 transform()한 결과인 label을 출력했을 때, 아래와 같이 뜬다.
<8x6 sparse matrix of type '<class 'numpy.float64'>' with 8 stored elements in Compressed Sparse Row format>
label에 toarray()메서드를 적용한 new_label을 출력해야지 다음과 같이 원하는 결과가 출력된다.
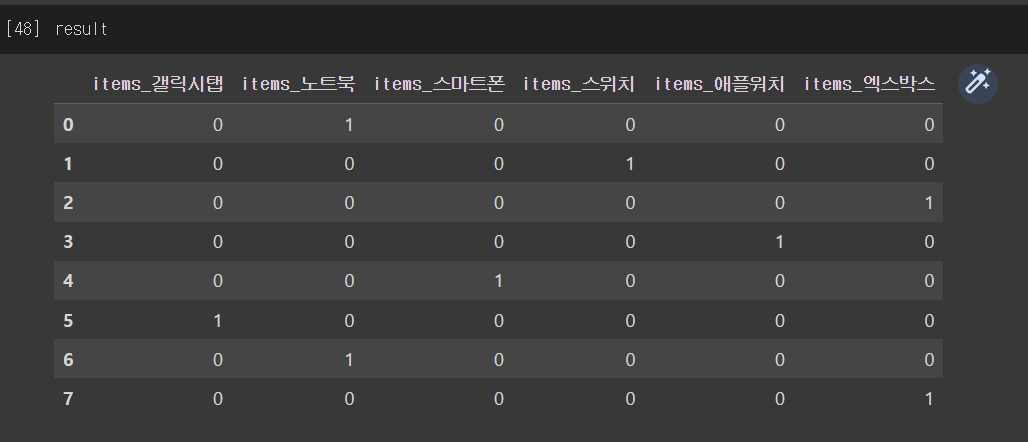
array([[0., 1., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 1.], [0., 0., 0., 0., 1., 0.], [0., 0., 1., 0., 0., 0.], [1., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 1.]])
실제 전처리를 할 때는 레이블 인코딩보다 원-핫 인코딩을 더 많이 사용한다고 한다.
간단한 레이블 인코딩을 두고 원-핫 인코딩을 사용하는 이유는 레이블 인코딩에서 각 피처를 숫자형 카테고리 값으로 변환하기 때문이다.
예를 들면, 위의 예제에서 엑스박스는 5의 값을 가지고 노트북은 2의 값을 가지게 되는데 특정 머신러닝 알고리즘에서는 이러한 값에 가중치를 두게 되면서 정확한 예측이 불가능하게 된다.
특히 선형회귀를 다루는 알고리즘에서 2의 값을 가지는 노트북보다 5의 값을 가지는 엑스박스에 더 큰 가중치를 둘 수 있기 때문이다.
때문에 대부분의 경우, 원-핫 인코딩을 써야 하는데 위 방식처럼 몇 번의 단계를 수행하기 번거롭다면 pandas를 이용할 수 있다.
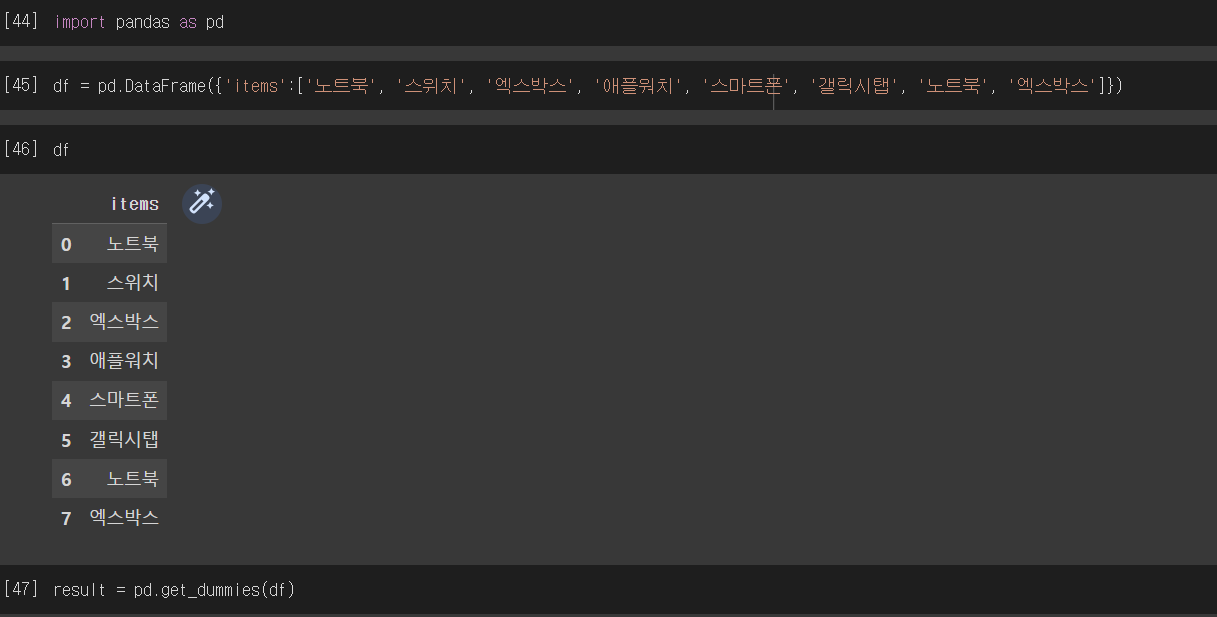
pandas의 DataFrame의 get_dummies()메서드를 이용하면 아래와 같이 한방(!)에 변환할 수 있다.
단지 get_dummies()메서드의 인자로는 dataframe을 넣어주어야 한다는 점만 주의하면 된다.
'ML' 카테고리의 다른 글
| 이진 분류 성능 지표 - 정확도, 혼동 행렬(AKA 오차 행렬), ROC곡선 (0) | 2023.05.22 |
|---|---|
| 선형회귀 평가지표 (with Scikit-learn) (0) | 2023.05.14 |
| 피처 스케일링과 정규화 (0) | 2023.03.27 |
| 활성화 함수 구현하기 (0) | 2023.03.27 |
| 반응형 머신러닝 앱을 만드는 가장 빠른 방법 - gradio (0) | 2023.03.04 |



